Highlights
- The CUDA architecture in PyTorch leverages the power of GPUs to speed up computations by using the parallel computing power of NVIDIA.
- Deep learning models are trained using GPU memory, which stores model parameters as well as intermediate activations.
- It’s really frustrating to get errors such as RuntimeError: CUDA out of Memory. Fortunately, we have some fixes to make this error go away.

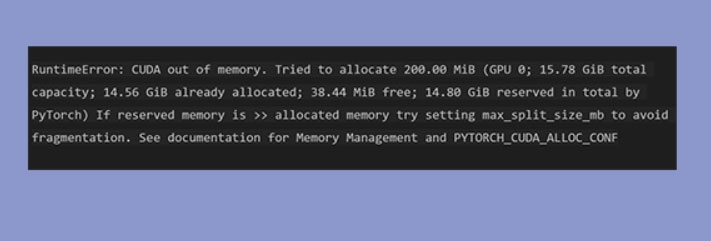
In the research and development community, PyTorch has become a popular deep-learning framework. In the case of large models or datasets, users may encounter the frustrating “RuntimeError: CUDA out of Memory” error.
This error indicates that the GPU’s memory has been exhausted, preventing deep learning from being completed.
Don’t want to miss the best from TechLatest?
Set us as a preferred source in Google Search
and make sure you never miss our latest.
In this article, we will tell you about some of the needed steps that may help you resolve the RuntimeError: CUDA out of Memory. Thus, without any further ado, let’s get started with the guide.
What is the CUDA Out of Memory Issue?
It is an integrated hardware and software technology developed by NVIDIA and stands for Compute Unified Device Architecture.
In this way, NVIDIA’s GPU can be used beyond image processing to develop C-compilers and to perform other operations. GPUs are, therefore, used for machine learning and other purposes by some program developers.
If you use PyTorch, Stable Diffusion, or another machine learning library, you may encounter the CUDA out-of-memory error.
What Causes ‘CUDA out of memory’ in PyTorch?
Python might show an error message “CUDA out of memory” for a variety of reasons. Here are a few of the most common causes:
- Generally, this error occurs when the batch size is too large when you train your model. To process more data simultaneously, you must increase the batch size, which requires more memory on your GPU. You’ll see the ‘CUDA out of memory’ error if your GPU cannot store the entire batch.
- You may also see this error if you use a large model architecture. When large models consume your GPU’s memory, your GPU’s performance can be severely hindered.
- Your model can quickly run out of memory if you fail to free up memory after each iteration. Utilize PyTorch’s memory management functions to keep system memory under control and proactively release variables once they are no longer required.
- PyTorch keeps track of all variables that require gradients by default. In the case of big models with large batches, this logging will quickly consume all GPU memory.
- Programs written in PyTorch can sometimes leak GPU memory, meaning they allocate GPU memory without releasing it after they are no longer required. Your GPU may run out of memory at some point, causing the error ‘CUDA out of memory’ to appear.
With the ‘CUDA out of memory’ error now identified, let’s look at solutions that may help you fix it.
How to Fix “RuntimeError: CUDA out of Memory”?
Here are some easy methods using which you can get rid of the RuntimeError: CUDA out-of-memory issue:
Fix 1: Changing the Batchsize
Reducing the batch size is the best option if you are using some pre-existing code or model architecture. Once you have cut the file in half, keep chopping it down until you are not getting the error anymore.
Even if you set the batch size to 1, if it still doesn’t help, other problems may need to be solved before larger batch sizes become effective.
In PyTorch, gradient accumulation is achieved by not calling optimizer.step() and optimizer.zero_grad() after every forward pass. A backward pass occurs once every ‘n,’ where ‘n’ is the number of steps to accumulate gradients over):
optimizer.zero_grad() # Explicitly zero the gradient buffers for i in range(num_mini_batches): inputs, labels = next(training_data) inputs, labels = inputs.to(device), labels.to(device) outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() # Backward pass to calculate the gradient if (i+1) % accumulation_steps == 0: # Wait for several backward passes optimizer.step() # Now we can do an optimizer step optimizer.zero_grad() # Reset gradients to zero
Fix 2: Use Mixed Precision Training
When using mixed precision training, your model can be trained with lower-precision data types, reducing the amount of memory it uses.
Modern GPUs feature more power than ever before, so mixed precision training uses this power to boost the performance of models without compromising accuracy.
While reducing memory usage and maintaining neural network performance, it utilizes 32-bit and 16-bit floating point types to maximize speed and efficiency.
Numerous parts of deep learning models, like activation functions, are not sensitive to precision. To reduce the memory footprint and speed up execution time without compromising model quality, half-precision calculations (float16) can be used.
With PyTorch’s torch.cuda.amp package, mixed precision training is relatively simple. In this package, amp.autocast is a Python context manager that allows the user to specify how precise operations should be performed.
model = ...
optimizer = ...
scaler = torch.cuda.amp.GradScaler()
for inputs, labels in data:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# Runs the forward pass with autocasting
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_fn(outputs, labels)
# Scales loss and performs backward pass using automatic mixed precision
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
You can reduce the memory usage of your model by as much as 50% by using half-precision (FP16) instead of single-precision (FP32). There may be convergence issues with PyTorch batch-norm layers.
To resolve this, ensure that your batch norm layers are float32 and remember to cast between float32 and float16 between each layer’s inputs and outputs when necessary.
torch.backends.cudnn.benchmark = True torch.backends.cudnn.enabled = True
Fix 3: Use a Smaller Model Architecture
Choosing a model architecture with a small memory footprint is crucial. Models with more layers or complex structures typically consume more memory during forward/backward passes if they have many layers or structures.
Using a smaller model architecture may be a good idea if you often run into ‘CUDA out of memory’ errors.
Performance is not necessarily compromised when you go for a simpler or smaller model. There is a wide variety of memory-efficient, high-performance models available online.
In terms of computational resources and model accuracy, MobileNet and EfficientNet provide a good trade-off. By using depth-separable convolutions, such architectures can reduce the number of parameters that can be trained without sacrificing accuracy.
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 16 * 16, 10) # Adjust the output size based on your task
Fix 4: Free Unused GPU Memory
With a torch.cuda.empty_cache(), you can manually clear GPU memory in PyTorch. You should incorporate this function after batch processing at the appropriate point in your code.
optimizer.zero_grad() loss.backward() optimizer.step() torch.cuda.empty_cache()
So, that’s how to fix the RuntimeError: CUDA out of Memory. It’s our hope that this guide has helped you. But suppose in case you have any questions or doubts regarding this topic on your mind, comment below and let us know.
Further Reading:
Enjoyed this article?
If TechLatest has helped you, consider supporting us with a one-time tip on Ko-fi. Every contribution keeps our work free and independent.
Support on Ko-fiDirectly in Your Inbox









